在昨天的文章中已經以比較科普的方式介紹了 diffusion model 的大略架構和運作方式(可以簡化成下面這張圖),但其實這樣的介紹只是便於理解而不夠精確的。
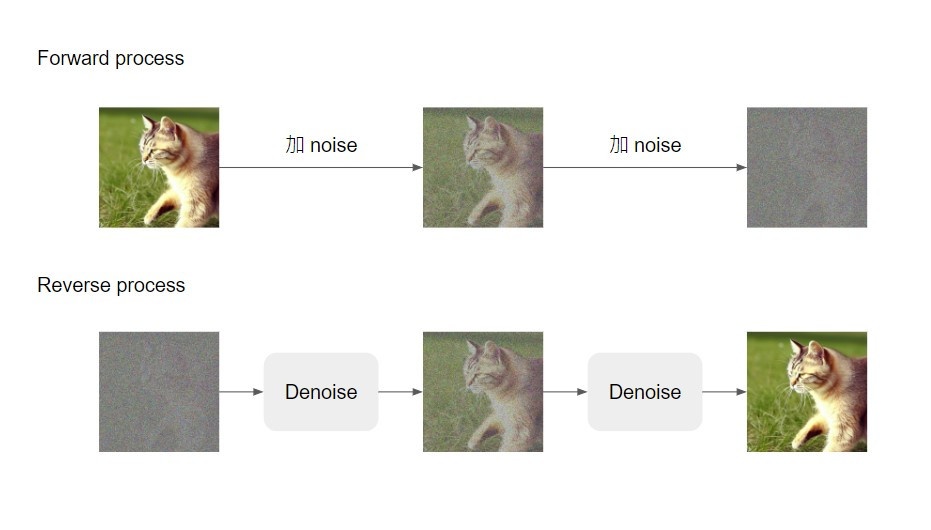
所以今天的文章,我會再稍微深入一點解釋 diffusion model 在訓練階段和影像生成階段的演算法~
訓練階段的演算法如下圖~
(圖片來源:Denoising Diffusion Probabilistic Models)
訓練 diffusion model 時,首先會從真實影像分布抽樣出一些影像 x_0,接著再從 1~T 的離散均勻分布抽樣出 t。t 代表的是先前提到的 denoise 階段或 noise 嚴重程度,它會決定原圖和 noise 混合的權重 α¯_t。
然後我們會從 Gaussian distribution 抽樣出 noise epsilon,接著依照 α¯_t 混合真實影像 x0 和 noise epsilon。值得注意的是,t 越大時 權重 α¯_t 越小,因此混合影像中的 noise 佔比就越大。
而 epsilon_θ 指的是 noise predictor,它就是要預設真實影像被加了多少 noise,因此學習目標就是讓 noise epsilon 和 noise predictor 的輸出 epsilon_θ 的差距越小越好。
以上這幾步驟會一直重複直到模型收斂為止。
看到這裡不知道大家有沒有發現,其實在影像上加 noise 不是每一個 step 多加一點,而是由 t 直接決定 noise 的嚴重程度,然後一次加到位。同理讓模型 denoise 也是一次去完。至於這麼做的原因,在之後的原理介紹會再解釋~

(圖片來源:Denoising Diffusion Probabilistic Models)
影像生成階段的演算法如上圖~看起來很簡單但其實暗藏玄機(?
首先會先從 Gaussian distribution 抽樣得到和預計生成影像相同大小的 noise 向量,接著會經過 T 次的 denoise。
然而不太直覺的是,在每次 denoise 的時候還要從 Gaussian distribution 再抽樣一個 noise z,並且在影像減去 noise predictor 預測的 noise 後,還要加上 z。這背後的原因,也會在之後的文章慢慢釐清~
今天就先這樣啦!明天開始要進入 diffusion model 原理的部分了~


 iThome鐵人賽
iThome鐵人賽